

Here’s another interview with an interesting translator for you! Previously, Martyna talked to David French, this time her guest is Jeremi Ochab.
Jeremi Ochab
Jeremi is an English-Polish translator of popular-science books and a researcher at the Jagiellonian University. He is a physicist and a linguist – these two don’t often come together, although we wish they would! We’ve always said that the forced division between the humanities and science is pointless, and Jeremi is the best example of all the benefits of combining diverse disciplines in one’s professional life. How come? Read on!
Physics and linguistics don’t seem to have a lot in common at first sight – how do you combine these two disciplines in your daily work?
Jeremi: I work as a researcher: I have an MA in English and a PhD in theoretical physics. I’m gradually moving away from physics, though, and I mostly deal with data analysis nowadays. For a couple of years now, I have cooperated with scientists from Argentina who do research on the human brain. For the time being, this is what most of my professional and scientific life focuses on. However, I always try to include the humanities in my research. For example, I apply quantitative methods in text analysis. Recently, I have written a historical-sociological research paper with my Czech colleague, based on the analysis of co-occurrence of signatures on Czech documents from the 13th century. The subject of my PhD was about computational tools similar to the ones used in this project: complex network analyses and theory.
These are theoretical aspects of data science; I sometimes use them in more practical applications when I analyse specific data. I cooperate with the Institute of the Polish Language of the Polish Academy of Sciences and the Faculty of Philology of the Jagiellonian University, in particular with the supervisor of my master thesis in English studies – Jan Rybicki – and its reviewer – Maciej Eder. They both specialise in stylometry, or computational stylistics, which consists in quantitative style analysis and comparison of texts, e.g. authorship attribution and verification.
Network analyses and machine learning methods may come in handy here – this is an immense field of science which has been applied in many areas of study for years and years now. We make use of that as well: artificial neural networks and some simpler algorithms. Our colleagues, for instance, successfully applied such methods to discover the real identity of Robert Galbraith. They managed to confirm – in a quantitative, statistical manner – that The Cuckoo’s Calling was in fact written by J.K. Rowling. They also investigated the case of Harper Lee, the author of To Kill a Mockingbird, as her authorship of the novel Go Set a Watchman, which she had published unexpectedly a year before she died, was questioned by some readers. I try to modestly contribute to this research as far as my schedules and abilities allow me.
All of this sounds very interesting, unconventional, and interdisciplinary – your work really spans a number of different subjects and fields.
Yeah, my work is rather eclectic and non-channelled. This is caused by the fact that I’m interested in ever so many subjects and I try to combine them. I keep seeking what tickles me most and I tend to end up getting to some weird territories.
So how did you come to study English?
I’m going to answer this question with an anecdote. In the third year of English studies, the new teacher of practical English classes asked us why we had chosen those studies. And I said that I simply liked the sound of the English language. She was really astonished! She found it surprising that a person could decide to study something only because they liked the sound of the language. In fact, phonology and phonetics were always my favourite subjects. Later on, my interests were directed elsewhere, for example to translation, but the aspects of the sounds of a language are still important to me.
Did being a physicist help you in any way when you studied English? Or was it somewhat problematic?
My mind and my personality are pretty analytical, which was reflected in my written assignments. They might have had some linguistic deficiencies, but they were coherent and logical, and that was appreciated.
When it comes to problems, it was difficult to be in several places at once, which is sometimes necessary when you study two programmes simultaneously. Luckily, the two faculty buildings were not located far away from each other at that time.
Another frustrating thing was that lecturers at the Institute of English Studies occasionally said something that was mathematically incorrect or used statistical terms or data in a wrong way ?. On the other hand, some lecturers had other degrees than English, too. One professor was a physicist, she used to work with particle colliders. Another professor, if I remember correctly, had a degree in mathematics but he specialised in pragmatics.
When I returned to the English studies after my year-long sabbatical, I chose the translation specialisation and then I happened to meet Jan Rybicki. As a stylometrist, he was vividly interested in collaborating with someone with a background in physics. He was aware that computational methods were something that the humanities had to come to terms with, at least to some extent. There are some aspects of research in the field of humanities that can make use of such methods and it was a good idea to start applying them in Poland at last. Obviously, linguists had used quantitative methods before, but at the Institute of English Studies, that was a new, fresh, interesting approach, introduced by Jan Rybicki. Introduced successfully, in the Polish context. This is a great field to explore. Digital humanities have actually seen rapid development recently.
Can you say a few words about digital humanities?
A definition I would offer is based on two areas of research that can be classified as digital humanities: disciplines which are preoccupied with digitisation of resources and disciplines which make use of the digital medium.
In the first case, it’s all about creating digitised data sets, preserved for the future generations in a durable form, well-annotated with metadata – this branch of digital humanities supports research in a systematic way.
In the other case, we’re talking about quantitative methods of analysis – from simple statistics to complex machine learning methods.
Both of these approaches can manifest themselves in various subdisciplines in a variety of ways. There are, for instance, 3D models of archaeological or architectural objects, map analyses, digitisation and automated annotation of artworks and museum collections. Creating digital works is also a good example here.
As far as language-related research is concerned, I can mention natural language processing methods which help annotate a language corpus (identify its grammatical, syntactical, and morphological features). Computers can do this 95% correctly, sometimes better than humans. Other examples include machine translation; chatbots, which have been getting better and better in the past years thanks to the use of algorithms that analyse and generate meaningful texts; speech processing. The humanities can fit well in any of these fields – the new media can be analysed in a much more systematic way and on a larger scale.
And how did you become the Polish translator of Thing Explainer?
I got hold of this beautiful book thanks to my university friends. I graduated from the English translation programme but I didn’t translate anything after graduation. My friends, however, did: at least some of them applied to various publishing houses and got their first jobs. One of my friends heard that Czarna Owca was looking for someone who would be able to translate Thing Explainer and she recommended me. Right on target! I am still grateful to her for picking me for that job. That was my first real translation commission and I believe it was also the most interesting and non-standard one.

In what way?
The full title of the book goes like this: Thing Explainer: Complicated Stuff in Simple Words. The ‘simple words’ mean that the author, Randall Munroe, used a frequency list of 1000 most popular words in English. That would be impossible in a regular book; there would be a lot more words. One thousand is a limitation that may turn out really problematic – when you start counting all function or grammatical words, you already get a couple of hundred of them, and then there are the content words: adjectives, nouns, verbs. Imagine a book, or a simple conversation for that matter, without metaphors. Even here, we’ve certainly used some: for example, ‘to turn out’ is a kind of spatial metaphor. And if a metaphor is built of some complicated words, they can’t turn up in a book like the one we’re talking about here: they’d need to be replaced with something else to make a phrase understandable. Anything you meant to say would have to be reconstructed piece by piece and rewritten in simpler words.

There’s a lot of that in the book; and that was its main limitation, resulting inherently from the main concept behind it, which is actually even highlighted on the cover. Another limitation, which may be less obvious at first sight, is space. There are lots of images: buttons, dials, switches, all with labels very cramped for space – so the Polish descriptions also had to fit in that limited space. This challenge is often encountered by translators who localise websites, where they need to squeeze items in tiny fields, retaining their meaning and clarity, without exceeding the available area. And this book is all like this.
I couldn’t shorten or omit anything, but I had to fit the words in the limited space. The publishing house decided against interfering with the graphic design, apart from some minor changes in the layout.
Another problem was that it wasn’t really so obvious for a translator to correctly read, understand, and interpret a text written this way.
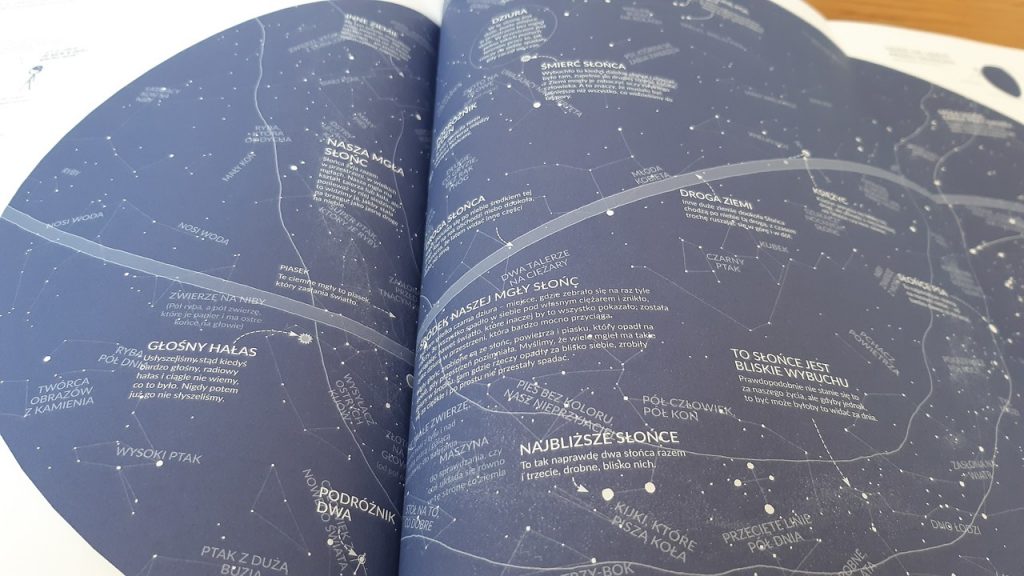
For me, reading this book is like solving a riddle.
You’re right! This book is just one big puzzle. If you think this book is for children… well, yes, as long as you read it together and explain everything along the way. And you won’t be able to do this as you go – you’ll need to consult Wikipedia all the time, to find out what particular fragments mean. And that’s what my work as a translator was like, in fact: constant checking and decoding.

Does this mean that drawing up the list of the most common words in Polish was actually the easiest part of the job?
Yes and no. The list was problematic from the very beginning. When I received the text to translate, I didn’t get the word list or any explanation to it. All I had was the title. I didn’t know in advance what the list contained. And that was actually the least of my worries – I simply decided to do a rough translation of the book and to make the final list afterwards. I worked with what I had and I drew up a preliminary list. I started by verifying the word statistics to make sure the author was telling the truth. He was, with a margin of error of a few words. Checking the author is always the first thing to do ?.
In the description accompanying his list, Munroe explains how it was created. He used a belles-lettres linguistic corpus as well as his own email correspondence; he also drew from his intuition and simply wished to be witty – and that’s how the list was made. I only found out about that when I translated the whole book. But before translating, I asked my colleagues from the Polish Language Institute to give me access to their corpora, divided into several subsets: belles-lettres, academic language, journalism, and speech. I also bought access to the Corpus of Contemporary American English, which is divided into similar sections. The first thing I did then was check which of the corpora was the best match for the translated book – what kind of language was the most adequate fit. Next, I checked how my translation matched the analogous subcorpus of the Polish language.
In the beginning, my list consisted of 1300 words, then I shortened and adjusted it. That was a bit painstaking: wondering, word by word, which item to replace or combine with another, or cut, or add. There was actually just basic engineering behind it. My translation was as faithful as possible, but it wasn’t always as clear as possible. Perhaps it could have been done more intuitively, but I decided to stick to measurable and verifiable criteria.
I’m really curious how this book was translated to other languages and what approaches other translators adopted. For me, that was a great adventure!

When it comes to the other books you’ve translated, which one do you find most interesting?
They were books of different sorts, popular science in general, six in total, and one of them has not been published yet (Fire in the Sky: Cosmic Collisions, Killer Asteroids, and the Race to Defend Earth by Gordon L. Dillow). I’ll talk about two books: one was very beautiful, and the other – very interesting.
The book which I find slightly less interesting but visually absolutely delightful is Planetarium published by the great Dwie Siostry. This is a book for children, so the editor who cooperated with me in that project helped me adjust the language to the needs of young readers, to make it clear and easy to understand. However, I don’t think that the way this book conveys information is actually adapted to children. This is just an encyclopaedia. There are successive chapters on particular subjects, explanations, footnotes, images. Because of its layout, where one page is dedicated to one subject, I was occasionally faced with the same challenge as in the case of Thing Explainer, namely: spatial limitations.
There is a lot of verifiable information in Planetarium – scientific knowledge is presented in a visually attractive way. The publisher commissioned me to do that job because I’m a physicist, so I’m meant to know my astronomy. As a translator, I have this nasty tendency to always check the author. Never believe the author! So I looked up every piece of information, I converted miles into kilometres, verified the accuracy of astronomical units, parsecs, and light years. That was an awful lot of work! I usually ask the publishers to contact my colleague, who is also a physicist, to provide final revision of factual errors. In the end, my role is to translate, not to cross-check facts and numbers. But if I do find an error, I always inform the publisher and then the editors can verify it.
What about the very interesting book?
The two versions of Astrophysics for People in a Hurry published in Poland by Insignis: that was quite a bizarre experience, one that doesn’t happen to translators all too often, I reckon. Astrophysics – this is a subject for readers who are at least a little bit interested in astronomy. After all, stars sell well. And one of the interesting gifts that translators can get from readers is feedback. There was one comment which surprised me a lot – and it was really funny. I usually sign with my middle name abbreviated to an initial – Jeremi K. Ochab. And one of the readers believed that was a joke, a reference to the star named Kochab in the Ursa Minor constellation. He thought I was posing as a star ?.
By the way, I found out that the author of the book, Neil deGrasse Tyson, had also made a factual error. I made the calculations three times, using various methods, because I couldn’t believe that there could be an error! The editor-in-chief of the publishing house is also a physicist, an ex-physicist, and when I told him I’d found a blunder, he also sat down to calculate it, to make sure I was right. The problem was that in a fragment about radioactive power supply for satellites, Tyson wrote that one pound of plutonium can generate 10 million kWh of energy to power a satellite for a long time. This is a huge number – he blew it up considerably. Why did he make the mistake? It turned out that Tyson had calculated the right amount of energy for a wrong physical process – a different type of plutonium decay. He simply mixed them up – happens to the best of us. I just have this annoying habit of checking all the information, which doubles the time I spend translating.
What did you mean by saying that the book was published in two versions?
There are two versions of the same book: Astrophysics for People in a Hurry (which is to say, for adults) and Astrophysics for Young People in a Hurry. They have different graphic layouts, and in this respect, the version for young people looks much better – there are lots of illustrations, astronomical pictures, and the content is organised differently. It also has an additional author, Gregory Mone, who helped Tyson edit the book to make it readable to the youth.
The Polish publisher sensibly decided that since I’d translated the first book, I should also work on the other. Because I had some scientific experience, I thought I could do something to help in the translation process: I compared the two versions. Some time before that, on Jan Rybicki’s invitation, I’d visited researchers in Göttingen who deal with text reuse: detecting the use of excerpts of texts in other texts. They even have their own software to find out in which places the text is the same, and in which it differs. And that was exactly what I wanted to know.

And how did you do that exactly?
My publisher assumed that the translation must be easy because that was basically the same book. But I wasn’t so sure and I wanted to estimate the actual amount of work. So I uploaded the two versions to the program, line by line, and the program showed me which sentences were identical, word-for-word, and which were different. In some cases, whole paragraphs were replicated, in other cases – they were only partially copied and the sentences had a different order. That helped me realise to what extent and in which fragments the text was reused.
Eventually, I had two options: either to translate the new text from scratch or to use the first version, to look into the original text, copy the identical paragraphs and sections, paying attention to what had changed. This could help me avoid doing exactly the same twice, so I decided to make use of the tool. This way, I also managed to prove it to the publisher that the texts were not really interchangeable – and that had an impact on my payment.
Additionally, I prepared frequency lists to see clearly how many words occurred in which version and how they overlapped. For example, in the book for adults, there are some words that aren’t used (or are hardly ever used) in the version for teenagers: they are usually related to the notions of government, nation, politics, etc. On the other hand, in the book for young people, there are words connected with their life: ‘teachers’, ‘students’, ‘games’. So there were some detectable differences. I was also able to discover that in the text for the youth, gerund verb forms were used more often (the -ing forms), just like pronouns, contractions (can’t, don’t), exclamative and interrogative phrases – in general, it was more expressive. The sentences were constructed differently and the phraseology was adjusted to young readers. The first text was a bit more ‘dry’, it alluded to ‘adult’ subjects, such as work. That was a marginal difference, but I had to take it into consideration.

Humour was another important issue. In the English youth-oriented book, there were some additional wordplays, and I needed to compensate for them somehow in Polish, which occasionally meant inventing a new joke from scratch. This proved difficult sometimes.
I don’t think translators often get a chance to translate almost the same book twice. This may not be the level of A Clockwork Orange, but it reflects the essence of what translation is – an exercise in mimicry.
What are you doing at the moment? Are you working on any translations?
I’m not. Since Fire in the sky, I haven’t had time to translate anything, for a number of reasons. So I’m not doing any translations at the moment. In the past, I would take a month off and translate the entire book within that time, more or less 180 standard manuscript pages. Mind you: this pace of translation is no good if you deal with belles-lettres, because as a result it might no longer be so belle ?.
Do you have any translation dreams? Is there anything you’d really love to translate?
There was this popular science book titled We have no idea that was really up my alley as far as sense of humour is concerned. But at the time, I was working on something else, so it was assigned to another translator. I wished I could translate it, but it’s too late now – one translation dream gone.
I hope your other translation dreams will come true. Thank you for the conversation!
Bonus
If you’re interested in the subjects mentioned by Jeremi, here’s a bunch of links to let you find out even more!
- http://cs.if.uj.edu.pl/jeremi/ – here, you can read in detail about Jeremi’s scientific interests and the books he’s translated
- https://www.ejournals.eu/autorzy/99999910136/Jeremi-K-Ochab/ – this is Jeremi’s research paper on the problems encountered by him while translating Thing Explainer – and guess what, Martyna got to translate the Polish version of the article into English – cheers to translators’ partnerships!
- https://ifa.filg.uj.edu.pl/ – IFA, or the Institute of English Studies at the Jagiellonian University in Kraków – Jeremi’s and Translatorion’s alma mater
- https://xkcd.com/ – website with comic strips created by Randall Munroe, the author of Thing Explainer